GPU-Beschleunigung in COMSOL Multiphysics®
Die neuesten Versionen von COMSOL Multiphysics® bieten neue Funktionen zur Beschleunigung von Simulationen mit NVIDIA® Grafikprozessoren (GPUs). Diese Verbesserungen erweitern die Bandbreite der Modelle, die von GPU-Hardware profitieren können. Dazu gehören Direct Sparse Solvers, die für alle Einzelphysik- oder Multiphysik-Anwendungen geeignet sind, sowie die Unterstützung für zeitexplizite Druckakustiksimulationen und das Training von Ersatzmodellen mit Deep Neural Networks (DNN). In Version 6.4 ist die GPU-Unterstützung für direkte Löser vollständig in das Standard-Löser-Framework integriert, sodass Benutzer die Vorteile der GPU-Beschleunigung für bestehende Modelle nutzen können, ohne Änderungen an den zugrunde liegenden physikalischen Einstellungen vornehmen zu müssen.
GPU-Beschleunigung für Direct Sparse Solvers
Eine der zeitaufwendigsten Phasen in vielen Finite-Elemente-Simulationen ist die wiederholte Lösung großer linearer Systeme. Solche Systeme entstehen durch implizite Zeitschritte, nichtlineare Iterationen, Eigenfrequenzanalysen und Parametersweeps. Um diese Art von Studien zu ermöglichen, enthält COMSOL Multiphysics® Version 6.4 nun den NVIDIA CUDA® Direct Sparse Solver (cuDSS). Dieser Löser führt Matrixfaktorisationen mit einer oder mehreren GPUs auf einem einzigen Computer durch und nutzt dabei die hohe Speicherbandbreite und den massiven Parallelismus der aktuellen GPU-Hardware.
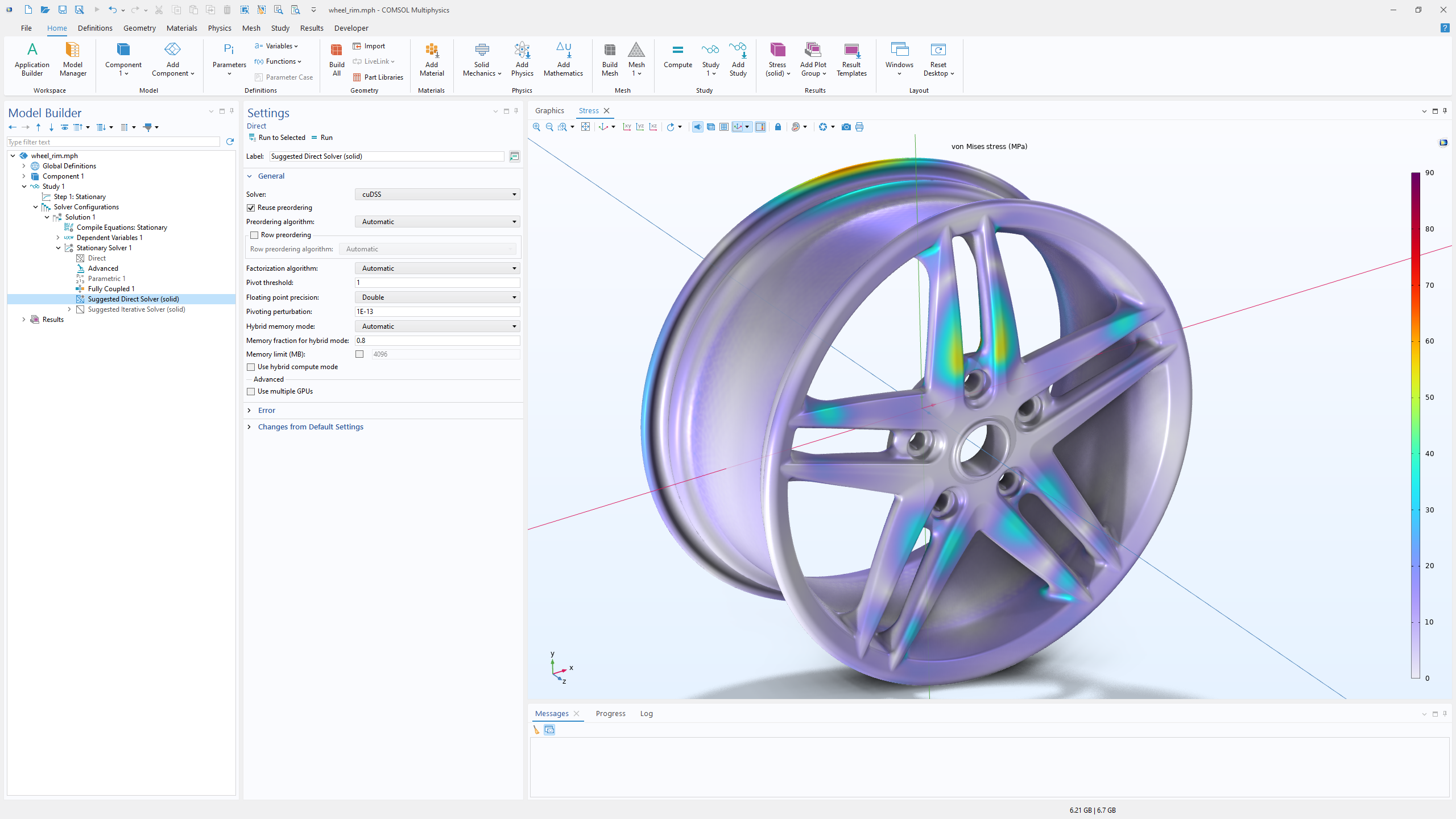
Die Leistungsverbesserungen variieren je nach Anwendung, jedoch wurden bei Modellen mit mehreren Millionen Freiheitsgraden erhebliche Zeiteinsparungen beobachtet. Beispielsweise führte die Lösung einer thermoviskosen Akustik-Benchmark-Simulation, die eine multiphysikalische Analyse der Schallübertragung durch eine perforierte Platte umfasste, auf mehreren NVIDIA® H100-GPUs zu deutlich kürzeren Laufzeiten im Vergleich zu einem Dual-Prozessor-CPU-System. Auch bei Standardmodellen der Strukturmechanik zeigen sich deutliche Verbesserungen, wenn die direkte Lösungsphase auf Workstation-GPUs wie die RTX 5000 Ada ausgelagert wird.
Die cuDSS-Implementierung unterstützt sowohl Doppelpräzisions- als auch Einzelpräzisionsarithmetik. Da die Einzelpräzision den Speicherbedarf um die Hälfte reduziert, kann sie die Leistung auf jeder Karte steigern, bei der die Anwendung speichergebunden ist, einschließlich kostengünstigerer GPUs. Ob ein bestimmtes Modell für die Einzelpräzision gut geeignet ist, hängt von seiner numerischen Konditionierung ab, die durch die Netzqualität, die Materialparameter und die zugrunde liegende Physik beeinflusst wird. Benutzer können die Präzisionsmodi direkt in den Lösereinstellungen testen und den Modus auswählen, der sowohl stabile Ergebnisse als auch die gewünschte Leistung bietet.
GPU-beschleunigte zeitexplizite Druckakustik
GPU-Unterstützung ist auch für zeitexplizite Druckakustiksimulationen verfügbar. Bei der Durchführung dieser Art von Simulationen kann die Notwendigkeit, große lineare Systeme bei jedem Zeitschritt zu lösen, vermieden werden, indem explizite Zeitschrittmethoden verwendet werden, die stattdessen auf wiederholten Vektoroperationen und lokalen Elementaktualisierungen basieren. Diese Operationen sind in hohem Maße parallelisierbar und lassen sich effizient auf GPU-Hardware durchführen.
Diese Fähigkeit ist besonders relevant für breitbandige Akustiksimulationen und große 3D-Gebiete, bei denen eine feine räumliche Auflösung zu einer großen Anzahl von Zeitschritten führt. Beispielsweise können Raumakustikmodelle, wie Büroräume oder Konzertsäle, Zehntausende von Zeitschritten erfordern, um die Wellenausbreitung genau zu berechnen. Durch die Auslagerung dieser Vorgänge auf GPUs kann die Gesamtsimulationszeit erheblich verkürzt werden.
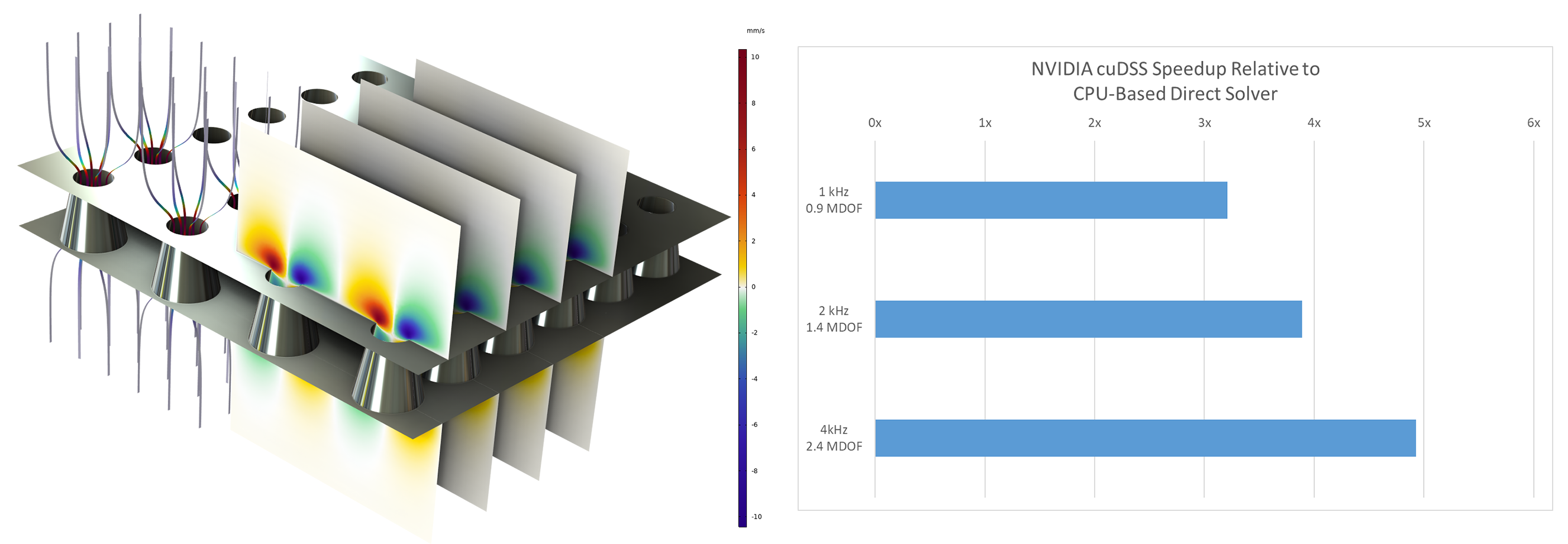
Die GPU-beschleunigte Formulierung für explizite Akustik unterstützt Single-GPU-Systeme (eingeführt in Version 6.3) sowie Multi-GPU-Systeme (eingeführt in Version 6.4), sowohl auf einem einzelnen Computer als auch auf Cluster-Knoten. Dadurch ist es möglich, Gebiete mit Hunderten von Millionen Freiheitsgraden zu simulieren. In einem wellenbasierten Modell einer Kammermusiksaal wurde beispielsweise eine Simulation mit etwa 300 Millionen Freiheitsgraden in wenigen Stunden auf einer einzigen NVIDIA® H100-GPU in Rechenzentrumsqualität durchgeführt, während dies auf mehreren CPU-Knoten mehrere Stunden gedauert hätte. Ähnliche Reduzierungen der Verarbeitungszeit lassen sich in Beispielen zur Automobilakustik und anderen groß angelegten transienten Analysen beobachten.
Bitte beachten Sie: Das Interface Pressure Acoustics, Time Explicit wird bei Verwendung einer einzelnen GPU für alle Lizenztypen unterstützt, erfordert jedoch bei Verwendung mehrerer GPUs eine Netzwerk-Lizenz (FNL).
Ausbreitung eines Impulses (mit einer Mittenfrequenz von 500 Hz) in einem Modell einer Kammermusiksaal mit 300 Millionen Freiheitsgraden, berechnet auf einer NVIDIA® H100 GPU in Rechenzentrumsqualität.
GPU-Unterstützung für das Training von Ersatzmodellen
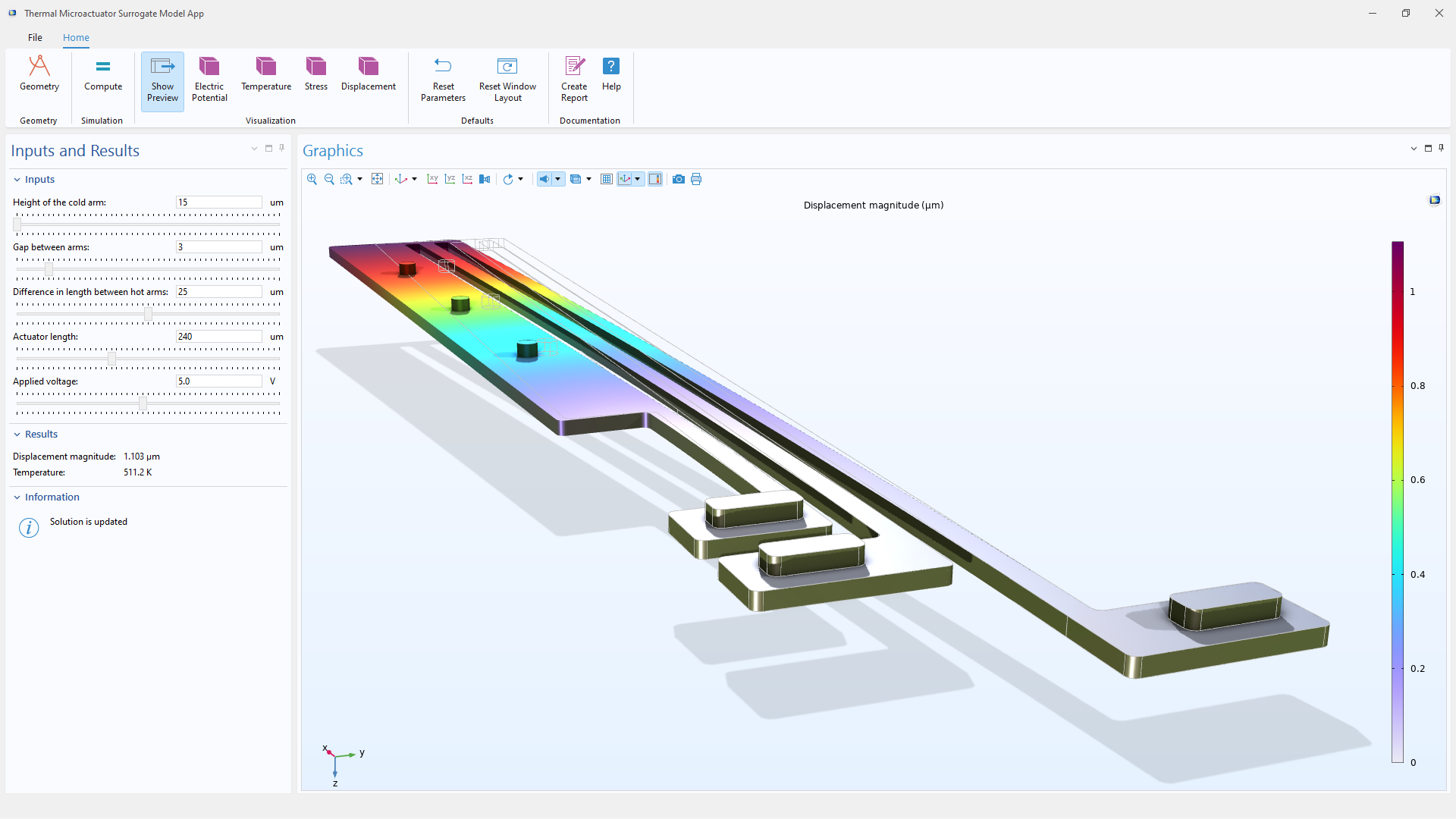
Seit Version 6.3 bietet COMSOL Multiphysics® auch Werkzeuge zur Erstellung von DNN-Ersatzmodellen, die hochpräzise numerische Simulationen approximieren. Das Training dieser Netzwerke erfordert die wiederholte Auswertung großer Datensätze und viele Optimierungszyklen, die sich gut für die GPU-Beschleunigung eignen. Durch die Durchführung des Trainingsprozesses auf einer NVIDIA® GPU können Anwender die Zeit reduzieren, die für die Untersuchung von Netzwerkarchitekturen oder die Anpassung von Hyperparametern erforderlich ist.
Größere Netzwerke, die möglicherweise für die Erfassung komplexer multiphysikalischer Verhaltensweisen oder die Rekonstruktion räumlicher Modelle erforderlich sind, profitieren ebenfalls von der erhöhten Speicherbandbreite und der parallelen Rechenleistung von GPUs. Die GPU-Unterstützung für das DNN-Training wird direkt im Interface Surrogate Model aktiviert und funktioniert ohne Add-On-Produkte.
Weitere Ressourcen
Weitere Informationen zur GPU-Beschleunigung in COMSOL Multiphysics® finden Sie hier:
- COMSOL Multiphysics® 6.4 Release Highlights: Neuerungen im Bereich Studien und Löser
- COMSOL Multiphysics® 6.4 Release Highlights: Neuerungen im Acoustics Module
- Systemanforderungen: COMSOL Multiphysics® Version 6.4
- Setting Up GPU-Accelerated Computing Within COMSOL Multiphysics®
NVIDIA, CUDA und RTX sind Marken und/oder eingetragene Marken der NVIDIA Corporation in den USA und/oder anderen Ländern. Intel und Xeon sind Marken der Intel Corporation in den USA und/oder anderen Ländern.